
Table of contents
Most clinical and biomedical research studies don't have a big data problem, but rather a complex data problem. In this article, you will learn the key concepts to understand this issue and analytical tools that help automate the exploration of complex data in biomedical research projects. Will you join me?
Over 20 Years of Big Data
It feels like it was just yesterday, but we have indeed been using the term big data for over twenty years now, generally referring to a type of project characterized by involving a large volume of information, generated at a dizzying speed from numerous sources, with a quality that we must control well and from which we hope to extract the maximum value.
In the field of clinical and biomedical research, the implementation of big data studies is almost exclusively focused on the -omics (genomics, proteomics, metabolomics, transcriptomics, etc.).
Experience in the sector leads us to identify a main reason for this focus:
The vast majority of clinical and biomedical research studies do not have a big data problem, but rather a complex data problem.
Complex Data?
As I previously described, big data studies present a number of intertwined challenges that especially impact the high cost of technological infrastructure and human resources involved, something that is difficult to justify under other conditions.
In general terms, complex data studies could be considered as a special case of the former and are characterized by two fundamental elements:
1. Focus on a relevant sample: the number of samples or individuals participating in the study (the famous statistical n) is manageable, in the best cases around the tens of thousands but mostly in the range of several hundreds. These individuals are also usually selected with pre-defined criteria. This, in turn, allows for significantly higher data quality than other types of study.
2. Integration of data: each of these study individuals is represented by a wide variety of information groups (demographics, diagnosis, prognosis, biomarkers, lifestyle habits, etc.) that come from different sources and must be appropriately integrated to have a complete view.
We could summarize, then, that complex data studies have the property that the number of variables involved is very high (multivariability), although the sample size may not be as large.
These combined elements create a very peculiar data context that presents a series of specific challenges, different from those of general big data studies.
On one hand, the formulation of the study objectives must incorporate a more open view, facilitating the search for results within a space of possibilities yet to be explored but with a logical (clinical) basis, and not focused on a specific hypothesis contrast. What at Butler Scientifics we call exploratory questions.
On the other hand, this space of possibilities is very extensive, motivated by the mentioned multivariability and by the existence of numerous subgroups of individuals (or strata), with particular properties, that can and should be studied both individually and globally.
This work context is what I call complex data.
Data Exploration
Thus, such a complex starting point becomes impossible to address with classic tools that require too much specificity in the objective (e.g., hypothesis-driven analysis) and, let alone, manually cover the combinatorial space of possibilities (e.g., tools for visualizing associations between variables).
However, it is worth noting that the smaller sample size of this type of studies allows the technology and resources that must be involved to have a cost several orders of magnitude lower than big data infrastructures.
To address this new scenario, there are other much more appropriate strategies, among which data exploration (EDA, acronym for Exploratory Data Analysis) undoubtedly stands out.
EDA is a term originally coined by John Wilder Tukey, an American statistician, who presented the concept and methodology in his famous book of the same name "Exploratory Data Analysis" in 1977.
Contrary to the confirmatory strategy (or CDA), data exploration is applied in that phase of the study whose goal is to connect ideas to identify possible "whys" of cause/effect associations or, in simpler terms, when the researcher wants to better understand what they have at hand.
Data exploration is thus a way of doing, an attitude applied over the data analysis process that, ultimately, seeks for the researcher to generate new hypotheses of greater scientific impact.
Data exploration proves very useful in different tasks such as:
- Simplifying the original problem
- Identifying lines of work with maximum potential
- Making the right choice of statistical methods for the analysis
- Reinforcing results obtained in previous studies
Exploration and Confirmation: A Perfect Pair
At this point, it is important to emphasize that the exploratory strategy is not, by any means, a substitute for hypothesis-driven study (or confirmatory strategy). In fact, as Tukey himself suggests (and as we explained some time ago in this article), when placed in sequence in the scientific process, they are an ideal complement:
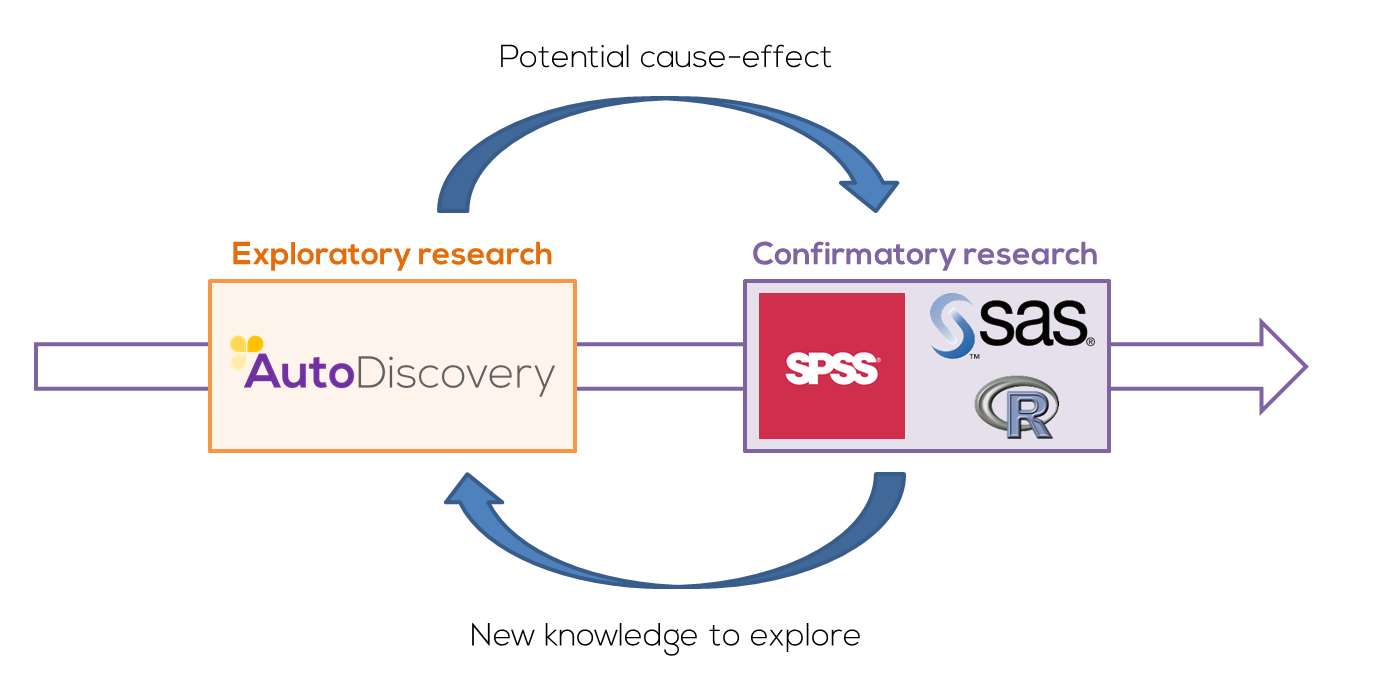
At the same time, the knowledge obtained from the confirmatory phase allows us to feed back into the process for future in-depth explorations.
Automated Exploration of Complex Data
While EDA stands out as one of the strategies to follow when facing a data complexity problem, by itself it does not answer the previously mentioned challenges: what kind of objectives should we formulate in an efficient exploratory study? How do we address the immense space of combinations we must face if we want to explore exhaustively?
The answer to these questions comes from a natural evolution of EDA: automated data exploration (automated EDA), a technique that combines basic concepts of data science automation (automated data science) with the experience of hundreds of real projects that have allowed us identifying key functional characteristics and, by extension, automate to a great extent the entire process.
Automating Data Exploration?
Indeed, data exploration is an intellectually intensive process that requires constant attention and a high level of knowledge in the study area.
Therefore, even partially automating this process implies that much of that knowledge has been digitalized or, if you allow me, "algorithmized".
Thus, any tool aiming to automate the exploration process should incorporate the fundamental elements of the "business" in which it will operate. For example, in the field of clinical and biomedical research, characteristics such as:
- Effective integration of data of different nature obtained from study individuals.
- Adjustment of the combination space to be explored according to scientific objectives.
- Definition of a typology of key results that is sufficiently generic yet practical. In the case of these clinical/biomedical studies, most results are expressed in the form of statistical associations between interest variables (treatment-response, group-characteristic, etc.) or in the form of behavior patterns (e.g., sequences of relevant events).
- Appropriate and intelligent choice of statistical methods for each case, always within the clinical scope (e.g., analysis of normality and variances, numerical correlations, Kaplan-Meier survival curves, advanced patient classification models, among many others)
- Exhaustive stratification of our sample, to explore each of the possible subgroups of interest in our study individually and, at the same time, compare these individual analyses.
- Prioritization of obtained results that effectively combine clinical relevance, effect sizes, and adjusted statistical significance, and allow focusing resources on the most valuable results.
- Traceability of obtained results, allowing for a transparent (white box) explanation and replicability of each of them.
Some Real Examples
Surely you already know that...
at Butler Scientifics we are data explorers
We have been automating this process for many years, and that's why we can share with you several real cases in different pathologies from the world of biomedicine.
Ah! And we also dare with other areas, like sports medicine... Here's an example.
Conclusions
In summary, compared to other alternatives such as confirmatory statistics or data visualization...
automated data exploration presents itself as an effective alternative to address the complexity context we face when undertaking a data analysis in the field of biomedical and clinical research.